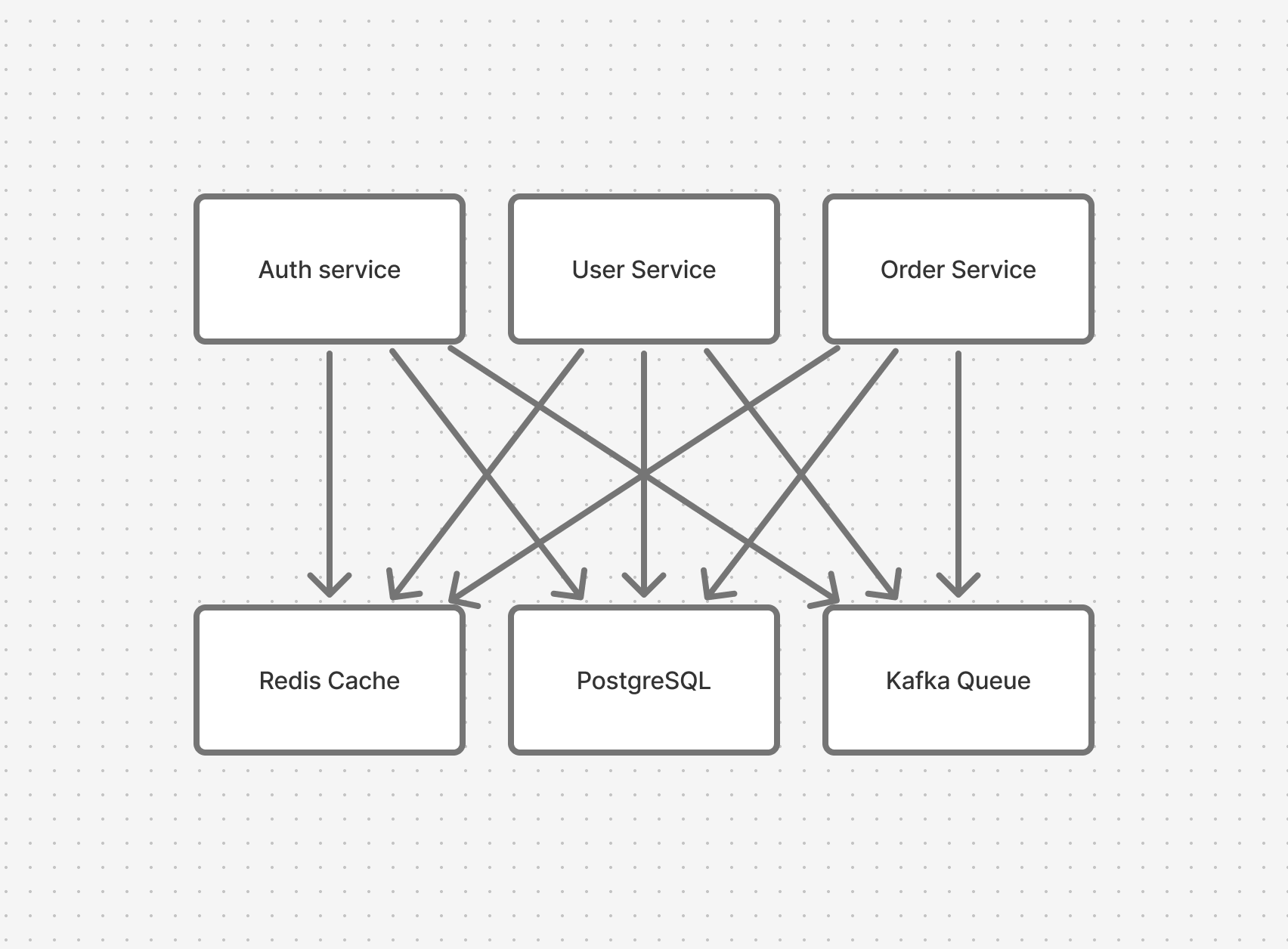
The typical backend architecture follows a familiar pattern. A web server connects to a database. Traffic grows, so you add Redis for caching. You need async processing, so you add Kafka. You need coordination, so you add distributed locks.
Every Solution Creates A Problem
As you add components to your architecture to solve problems as you scale, in turn you create new problems for yourself:
- Caching: brings cache invalidation bugs, stale data, and thundering herd problems.
- Message queues: bring message ordering issues, exactly-once delivery problems, and dead letter queue monitoring.
- Pub/sub systems: bring subscription management complexity, message replay challenges, and coordination overhead.
- Distributed locks: bring deadlocks, lock timeouts, and split-brain scenarios.
- Multiple services: bring distributed transactions, eventual consistency, and network partition handling.
Worse, these are bugs you can’t unit test for. They’re emergent behaviors that only appear under load when it matters most.
Yet it’s accepted as the way things must be. Nobody got fired for adding Kafka, Redis, and RabbitMQ to the stack. The fact that each one brings its own failure modes is assumed to be the growing pains of any successful business.
How We Got Here
Looking back at the very first thing you did when starting your application: setting up a web server and a database. The way you’ve designed your app is through an age-old practice of “separating state and compute.”
We’ve been doing it this way since the 1980s, when client-server architecture put databases on their own machines.
This came from the fact that computers were slow and had limited resources. Running application code and database operations on the same machine meant they’d fight over CPU and memory, making both perform poorly. Separating them protected databases from compute overhead.
This tradeoff made sense when CPU and memory were severely limited, but the pattern outlived its purpose. As traffic grew, we added caching layers, message queues, and distributed locks — each solving a problem from the last without questioning the original assumption of how we got here.
40 Years Later
Those constraints from forty years ago no longer apply to today’s servers. Modern CPUs are orders of magnitude faster, and memory is abundant and cheap. Application bottlenecks have shifted from local compute to network latency and locks.
This is best demonstrated with a simple comparison between a real-world Postgres query over the network versus a SQLite query on the same machine: A Postgres query over the network takes 1-10ms over LAN. The same query on a local SQLite database running in the same process as your application takes 0.01-0.1ms, roughly 100x faster. (These benchmarks are heavily dependent on the workload, this is a conservative performance number for SQLite.)
That 100x difference is not about switching to a marginally different database, it’s about rethinking your architecture for modern computers by eliminating the centralized database completely in favor of databases colocated with your compute. Combining compute and state removes the biggest sources of latency in modern applications.
The Actor Model: Combining Compute and State
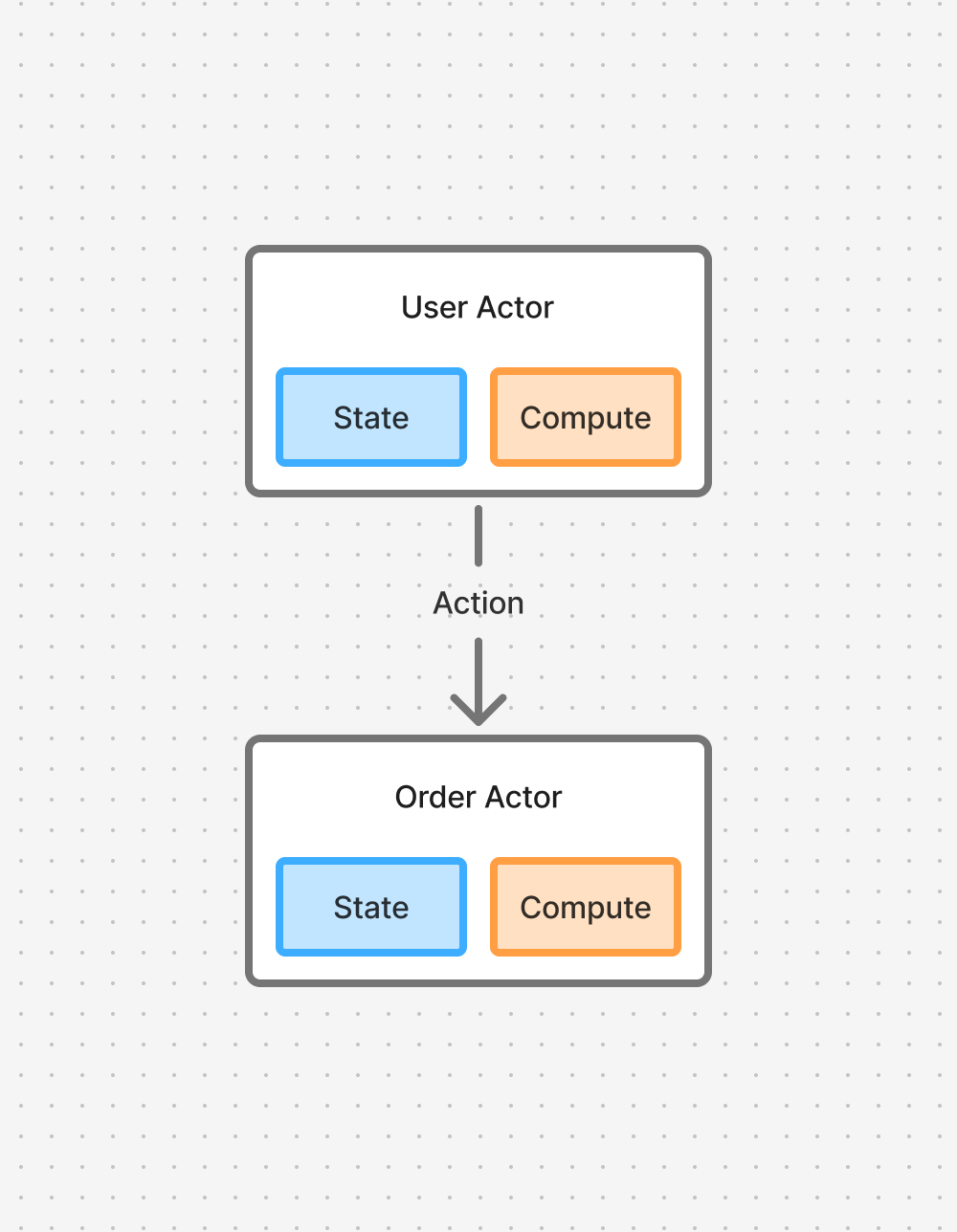
Actors take the completely opposite approach to “separating compute and state:” they merge state and compute together.
Each actor’s state is isolated to itself and cannot be read by any other actors. Instead, you communicate with actors over the network via actions.
They’re like mini-servers: they can accept and respond to network requests and even send network requests themselves. They remain running as a long-lived process with in-memory state until they decide to go to sleep.
In addition to performance and complexity benefits, this architecture eliminates entire categories of bugs by design. No network to the database means no network partitions. No shared state means no race conditions. No locks means no deadlocks.
The 4 Properties That Eliminate Complexity
By combining compute and state, actors present a few key properties that eliminate entire categories of problems. These properties are the core of the design patterns that we’ll discuss in further articles.
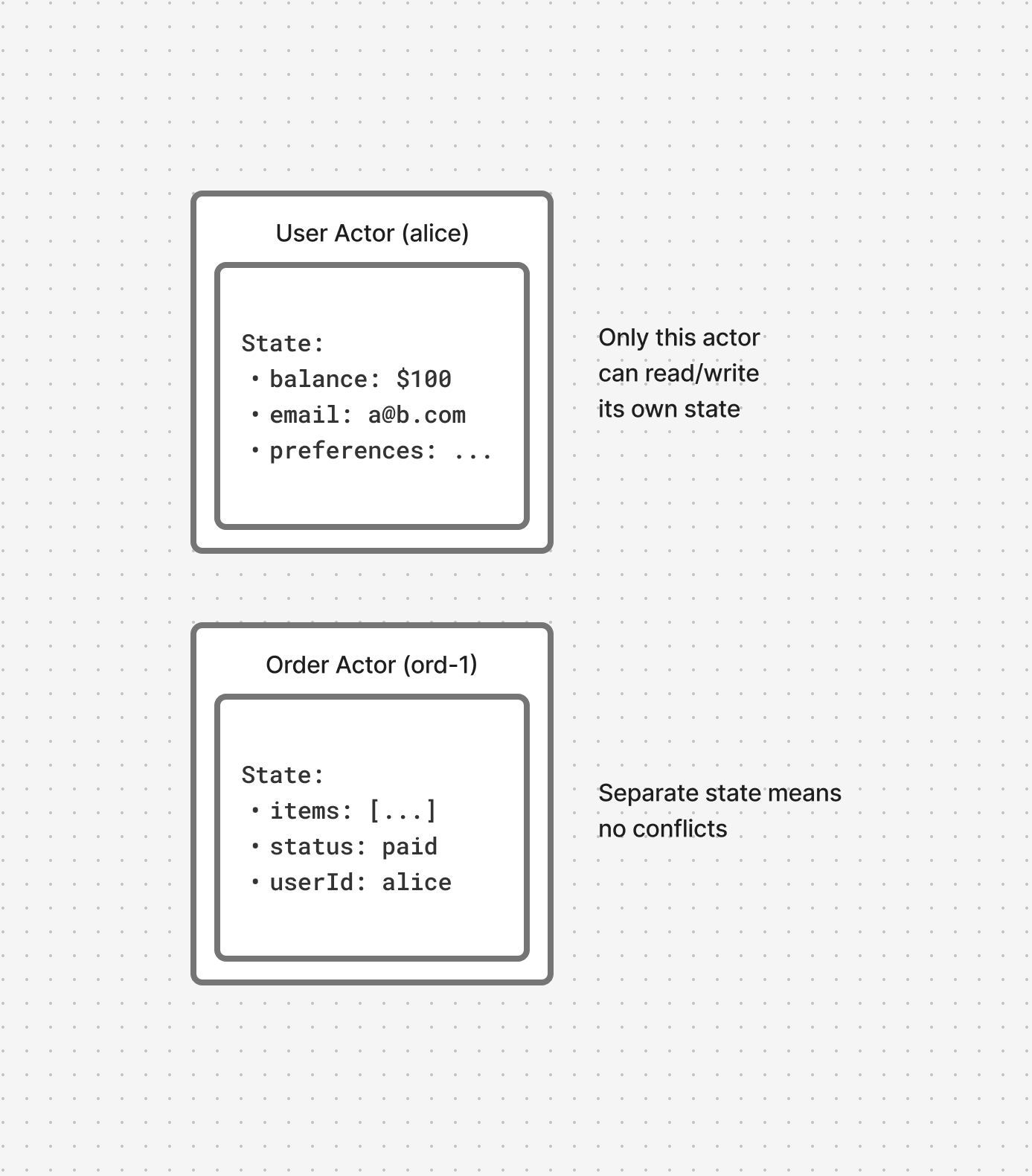
Isolated State
Each actor manages its own private state. No other process can access an actor’s state.
This eliminates race conditions (can’t happen when only one process touches the data), deadlocks (no locks means no deadlocks), cache invalidation (no shared cache to invalidate), and read-after-write inconsistencies (your writes are immediately visible to you).
Debugging becomes straightforward: the actor’s state is the single source of truth. There’s no need to reconstruct state from multiple systems or reason about eventual consistency across caches, databases, and message queues.
As your app grows, new features affect a limited number of actors which have a limited scope. Changes don’t ripple through shared state across services or risk breaking unrelated parts of your system.
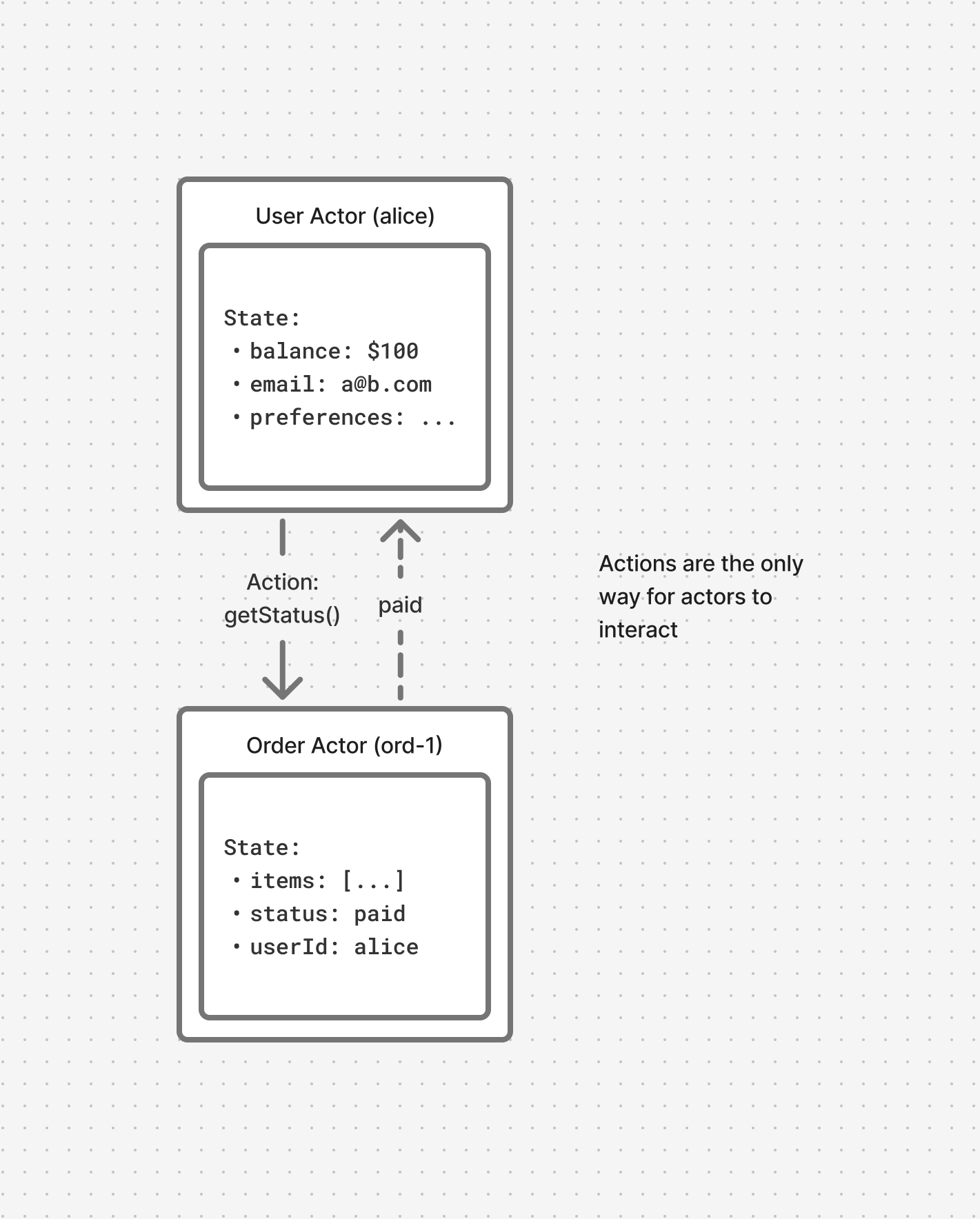
Message-Based Communication
Actors talk through actions and events, not direct state access. This makes it easier to scale actors since they can scale horizontally across multiple machines and still communicate efficiently.
Messages sent to actors are automatically queued and processed sequentially. This almost always eliminates the need for external message queues since backpressure, ordering, and delivery are handled by the actor runtime itself.
Crucially, actors frequently talk to each other to build larger systems that scale well. We’ll be talking a lot about patterns like this in this course.
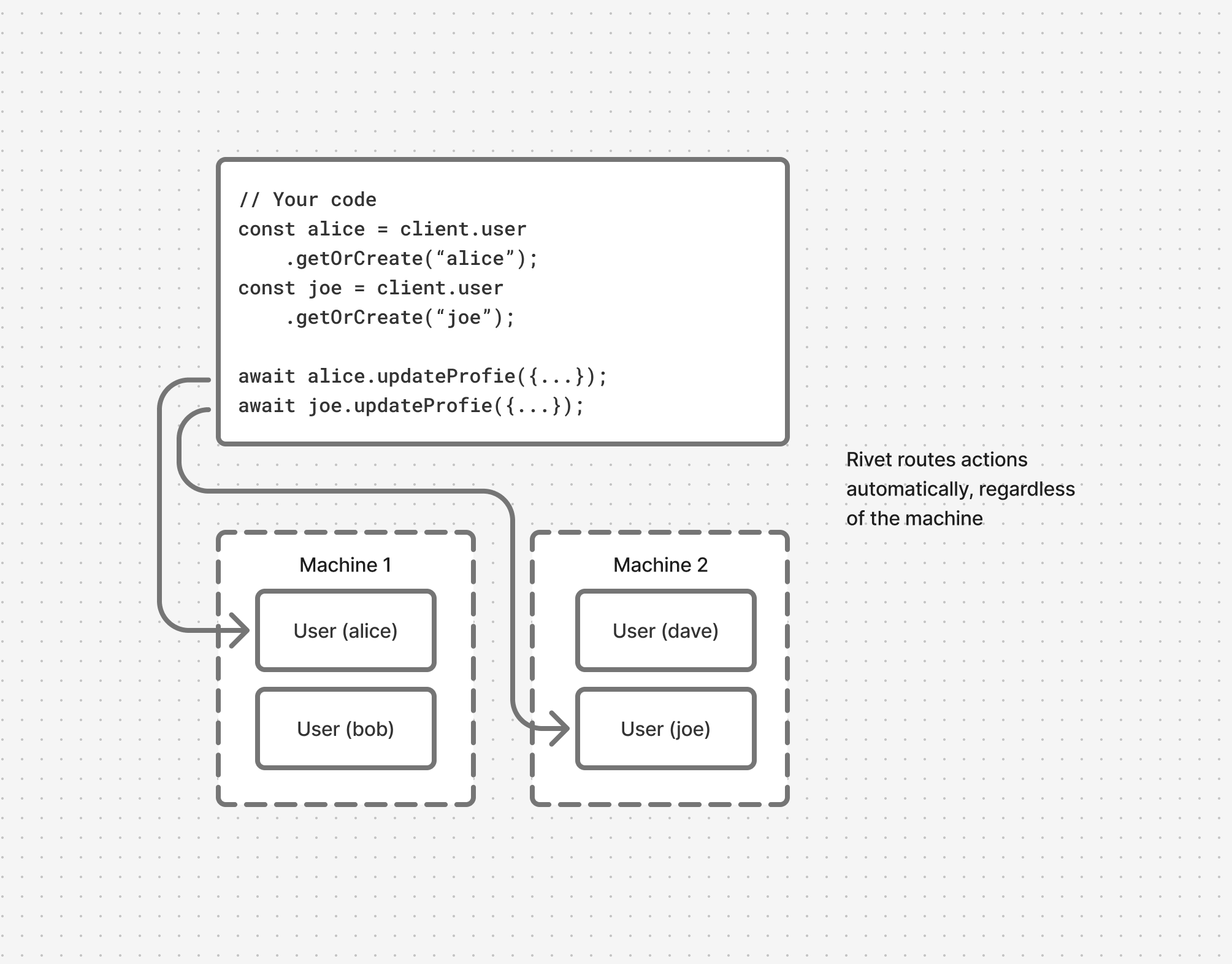
Location Transparency
Actors can run on any machine in a cluster and still send messages between actors regardless of the host machine. Rivet automatically handles intelligent load balancing of actors and routing between actors.
The same code will run whether you have 1 or 1,000 machines without complex network configuration, DNS, or pub/sub systems.
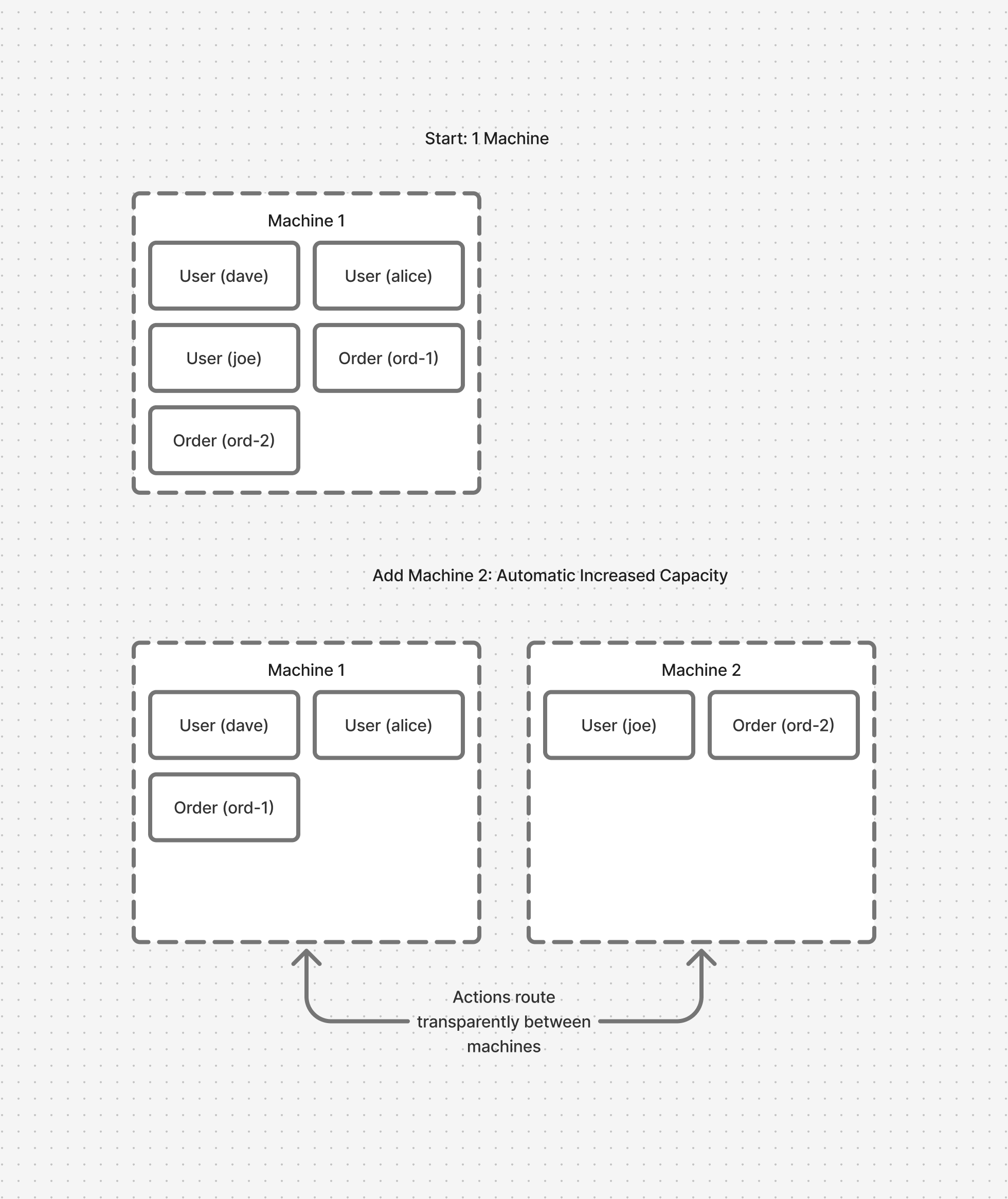
Horizontal Scaling
Actors are designed to transparently interact with other actors regardless of what machine they run on. This makes actors easy to scale by just adding more machines for actors to run on when you need it.
Load spreads naturally since actors are small, lightweight units. No complex sharding logic or coordination needed.
Putting It All Together: A Radically Simpler Architecture
When you build your backend with actors, the four properties listed remove the need for:
- Redis/Memcached: Caching is built-in (state already lives in-memory with compute).
- Kafka/RabbitMQ/SQS: Message queueing, events, and async messaging are built-in to the actor runtime.
- NATS/Redis Streams: Pub/sub is built-in to actors through message passing and events.
- Consul/etcd/ZooKeeper: No distributed coordination needed, actors encapsulate their own state and the runtime handles discovery and routing automatically.
- Istio/Linkerd: Actors handle routing and discovery automatically.
- Database sharding: Actors distribute themselves automatically. No shard keys, no rebalancing logic, no cross-shard queries.
If Actors Are So Great, Why Aren’t They Everywhere?
If you’ve reached this point and are unfamiliar with the actor model, you’re probably asking this exact question. It all sounds a little too rosy.
The truth is that actors are used widely — just not visibly. Large enterprises with engineers who’ve spent years wrestling with traditional architectures have long since adopted them. The pattern has proven itself at massive scale:
- WhatsApp (notoriously acquired for $19B running Erlang/OTP with only 35 engineers)
- Discord
- X
- PayPal
- FoundationDB (powering Apple, Snowflake, DataDog)
So why hasn’t the actor model spread to smaller teams and mainstream development?
This mirrors TypeScript’s trajectory. It started as a niche tool for large codebases — most developers dismissed it as unnecessary overhead with poor tooling. But as more developers felt the pain of loose typing at scale, adoption grew. Today, TypeScript is a non-negotiable for many teams because of that collective suffering.
Actors are on the same trajectory. The pain of distributed systems complexity is becoming impossible to ignore.
Other ecosystems have had mature actor frameworks for years — Erlang has OTP, Java has Akka, C# has Microsoft Orleans. But TypeScript has been the missing piece until recently with:
- Rivet Actors: Open-source actor infrastructure for TypeScript
- Cloudflare Durable Objects: Leverages Cloudflare’s existing network & JavaScript runtime
What To Expect From Act I
This act will cover common design patterns based on the 4 principles listed above for building modern applications with actors.
We’ll also discuss common anti-patterns when designing with actors and situations where actors may not make sense.
See the table of contents for a full list of content.